● RV770核心架构图:
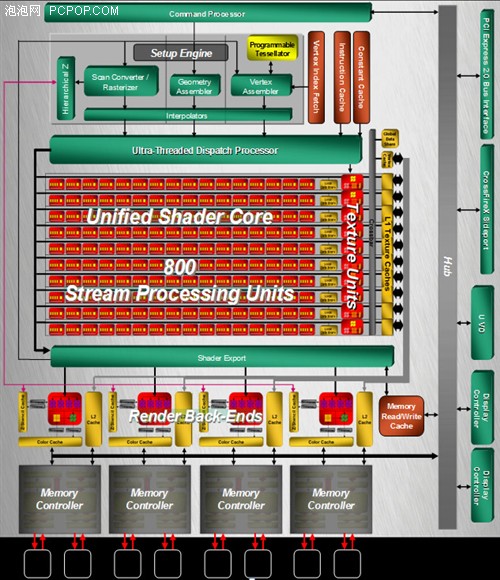
基本上,RV770和RV670的整体结构是相同的,RV670身上所有的模块都得到了沿用,但很多模块都经过了重新设计或者优化设计: 1。SIMD阵列扩充为10组,每组SIMD绑定专属缓存及纹理单元; 2。纹理单元数量扩充为10组,寄存器容量增加; 3。继续提升几何着色的效率,适应未来DX10游戏的需要; 4。改进可编程镶嵌单元,使之更适合于动画游戏实时渲染; 5。改进显存控制器,率先支持GDDR5,并加入显存读写缓冲区,增强数据读写命中率。 ● RV770核心规格全面翻倍: 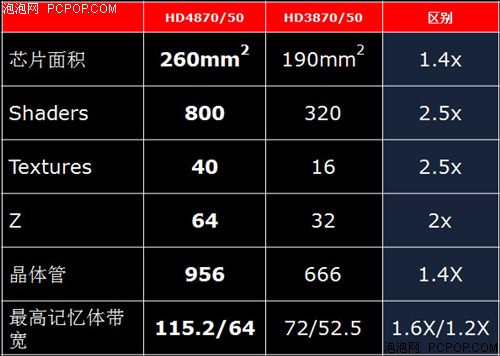
翻倍的规格是最容易理解的,但数字部分往往比较抽象,下面就详细介绍各个模块的具体含义。 RV770核心最显著的特点就是将流处理器提升到了空前的800个,达到了RV670的2.5倍!实际上除了流处理器之外,纹理单元、光栅单元都得到了大幅增强。 ● 流处理器翻2.5倍:

RV670是4组SIMD,每组16个Shader,每个Shader 5个流处理器 RV770是10组SIMD,每组16个Shader,每个Shader 5个流处理器 在SIMD和Shader规模扩大的同时,Ultra-Threaded Dispatch Processor(超线程分配处理器)也变得更加复杂。由于每组SIMD所包括的Shader数量增多,阵列内的Arbiter(仲裁器)和Sequencer(定序器)数量同比增加至20个,因此扩充规模后的RV770单个Shader执行效率并不会下降。 ● 纹理单元翻2.5倍:
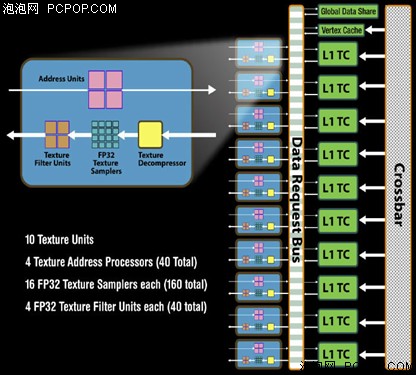
RV770的纹理单元数量相比R600/RV670翻了2.5倍,从4组增加至10组,这样RV770总共就是40个纹理单元,Shader和TMU的比例达到了4:1。 每组纹理单元内部包含了4个纹理寻址单元(黄色,共40个),16个32位浮点纹理采样单元(橘黄色,共160个),和4个纹理过滤单元(深红色,共40个)。
● 光栅单元数量不变,规格翻倍:
RV770还是保持4组后处理单元,也就是通常所说的16个。但这次AMD重新设计了光栅单元的内部结构,以改善R600/RV670那低下的AA效能。
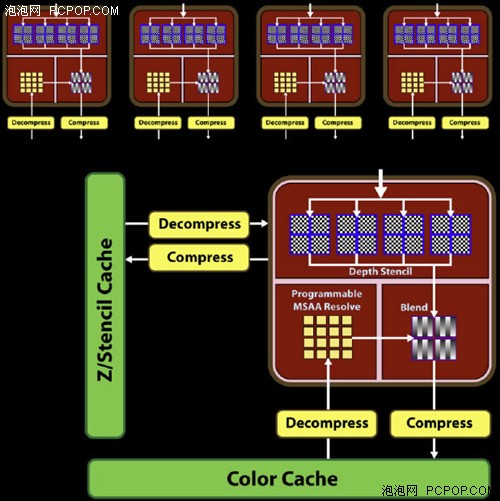
R600/RV670每组后处理器单元内部包括了8个Z/模版采样,而RV770将采样数量提高至16个,多重采样(MSAA)速度直接翻倍,AMD声称RV770可以提供几乎免费的2xMSAA效能,并且4x/8xMSAA效能相比上代提升非常显著。
RV770的AA算法最终还是交给Shader部分来处理,好在RV770的流处理器高达800个,多数情况下都处在性能过剩状态。2倍的Z/模版采样率再加上2.5倍的Shader规模,RV770的抗锯齿性能将会有一个质的飞跃
RV770核心不仅仅是把核心各个模块的数量翻倍这么简单,实际上在微架构方面还做了不小的优化,这方面相信很多朋友还不容易理解,下面就做一个简单的说明。
● 压缩晶体管密度,每平方毫米晶体管性能提升40%
在GPU最关键的流处理器部分,RV770与RV670的结构是完全相同的,RV670拥有4组SIMD(每组SIMD包括16个Shader,每个Shader有5个流处理器),RV770是10组SIMD,可以说在流处理器部分只是单纯的扩充了规模。不过,这次ATI通过另外一种“投机取巧”的方式提高了RV770核心的“效能”——压缩晶体管,或者说是提高硅片的利用率。 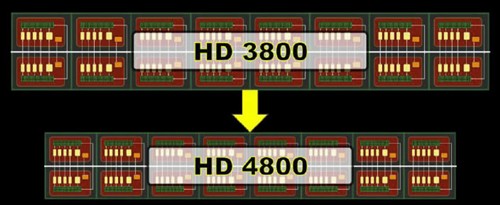
同为55nm工艺,RV670和RV770的SIMD阵列所占体积不同
通过上图就可以看出,从RV670到RV770,每组SIMD阵列所占用的芯片面积缩小了40%,如此一来每平方毫米晶体管所能提供的性能就提高40%。在架构和结构不变的情况下,能获得如此巨大的性能提升,看来AMD对于55nm工艺的运用已经达到了炉火纯青的地步!

RV770核心各部分模块示意图
现在我们就可以理解,同为55nm工艺,为什么7.54亿晶体管的G92核心面积高达230平方毫米,而9.56亿晶体管的RV770核心面积只有256平方毫米!因为RV770的晶体管密度更大,G92b作为NVIDIA首颗55nm的GPU,看来晶体管密度还不够高,没有充分利用硅片面积。
RV770核心晶元切割示意图
减少芯片面积的优势是不言而喻的,意味着一块晶元上能切割出更多的GPU核心,这样制造成本就会下降。当然与成本息息相关的还有芯片良品率的问题,RV770的晶体管密度如此之高,可能会影响良率,而且发热过于集中的问题会比较棘手。
● 纹理单元全新的缓存设计
前面已经提到RV770相比RV670纹理单元的数量翻了2.5倍,在数量增加的同时,一二级缓存的容量和带宽都随之改进,以确保存取效率。 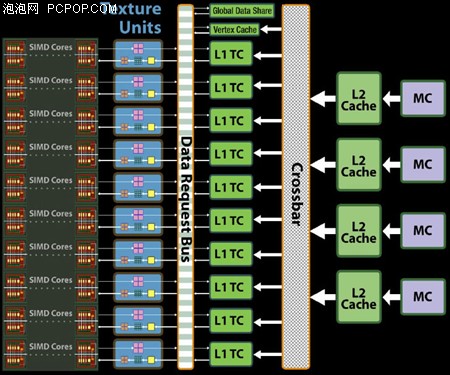
- 顶点着色拥有独立专署缓存
- 每一组SIMD阵列拥有单独的一级缓存(L1 TC)
- RV770核心相比RV670,L1 TC容量翻倍,总L1容量达RV670的五倍!
- 在显存控制器和显存颗粒之前拥有二级缓存
- L1纹理缓存存取速度高达480GB/s
- L1和L2缓存之前的带宽高达384GB/s
● 抗锯齿效能翻倍:
在之前HD4850的评测中我们已经发现,其AA效能大幅超越HD3870,和9800GTX/+相比也能够反败为胜,而且AA等级越高优势就越明显! 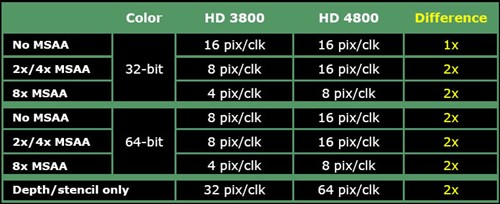
可以看出,全新的ROP单元大大加强了RV770核心的多重采样效能,如果不开AA那么RV770就没什么优势,一旦打开2x/4x/8xAA,那么它惊人的实力就会被完全释放出来。
由于目前玩家们对游戏画质的要求很高,抗锯齿基本上成为了每个游戏的默认特效,再加上目前高端显卡的实力够强,在打开AA的情况下都有不错的FPS,因此4xAA应该是基本配置,更何况微软已经将4xMSAA列为DX10.1的默认标准,所以高端显卡的性能应该以打开4xMSAA为准。 | 







 发表于 2008-8-25 14:42:27
发表于 2008-8-25 14:42:27
 分享
分享 收藏
收藏














